Abstract
Continuous multimodal representations suitable for multimodal information retrieval are usually obtained with methods that heavily rely on multimodal autoencoders. In video hyperlinking, a task that aims at retrieving video segments, the state of the art is a variation of two interlocked networks working in opposing directions. These systems provide good multimodal embeddings and are also capable of translating from one representation space to the other. Operating on representation spaces, these networks lack the ability to operate in the original spaces (text or image), which makes it difficult to visualize the cross-modal function, and do not generalize well to unseen data.
Recently, generative adversarial networks have gained popularity and have been used for generating realistic synthetic data and for obtaining high-level, single-modal latent representation spaces. In this work, we evaluate the feasibility of using GANs to obtain multimodal representations.
We show that GANs can be used for multimodal representation learning and that they provide multimodal representations that are superior to representations obtained with multimodal autoencoders. Additionally, we illustrate the ability of visualizing crossmodal translations that can provide human-interpretable insights on learned GAN-based video hyperlinking models.
Overview
When fusing multiple modalities, there are multiple options when choosing the initial modalities we provide to a fusing model. In all generality, we could classify the initial single modal modalities in three categories:
- continuous representations - e.g. Word2Vec or skip-thought vectors for text chunks and CNN features from higher layers to represent video frames
- concepts - e.g. keywords extracted from speech transcriptions and visual concepts (like ImageNet categories), which are then embedded (with a simple LUT, Word2Vec or a custom architecture
- initial domains - e.g. the text domain for speech and the RGB spatial space for images, which are then modeled and represented end to end within a slightly more complex architecture
Previously, we explored methods of fusing high quality continuous single modal representations into high performing multimodal embeddings. We did so by using a new crossmodal architecture (BiDNN) with additional restriction, resembling multimodal autoencoders, and confirmed the new state of the art in a live setup at TRECVID 2016's video hyperlinking evaluation, where we obtained the best results.
Such methods offer high quality multimodal embeddings are are fast/easy to train. Their only potential downside is that, as many neural networks, they are often treated as black boxes. A network like BiDNN performs crossmodal translations to achieve multimodal embedding and it should thus be possible to visualize the model by finding real samples that are closest to a crossmodal translation of the network from one modality to the other (e.g. given an input speech segment, let's find a video frame closest to the translated representation in the video modality and see what the model is expecting in the other modality). This is however approximative and slightly suboptimal.
Given the recent recent surge of generative adversarial networks and their astonishing single modal representation spaces, I began to wonder if they could be used both for multimodal embedding and as a different way of, again, performing multimodal fusion through crossmodal translations but this time, while retaining the possibility to synthesize into the original domain (e.g. rgb spatial domain) instead of stopping into the continuous representation domain
We used the architecture from the recent paper entitled "Generative Adversarial Text to Image Synthesis" with very minor modifications:

The network consists of a generator networks and a discriminator network. Given a random variable z and embedding of a current speech segment, the generator network tries to synthesize a realistically looking video frame that would match the corresponding speech segment. The discriminator networks received both an image and a speech embedding and tries to see if the pair is realistic (real) or unrealistic (fake/not matching). As with all GANs, it's a "min-max" like setup, where the two competing networks (or better, their propagation of losses) improve the results. The networks (as a whole) is trained by providing the discriminator with three sets of samples:
- {real image, real text} - we give the discriminator a matching image and a speech segment from a real video segment
- {incorrect image, real text} - we give the discriminator a non matching image-speech segment from two random different video segments
- {synthetic image, real text} - we give the discriminator the real text and the image from the output of the generator. During training, backpropagation does not cease at the 1st layer of the discriminator but it continues to the generator and it updates its weights.
It's important to remember that, just like with multimodal autoencoders / BiDNNs, this is unsupervised learning, so everything is done on one dataset and there is no train/test split. This is why we use a random image from another video segment and not specifically a video segment that is unrelated (completely different topic) to the video segment providing the speech modality, as that would require a training groundtruth. We update the generator 4 times more often than the the discriminator since a well performing discriminator (which will converge faster) would prevent the generator from further converging due to very small gradients.
We're interested in two things:
- given that the discriminator deals with two modalities, can it provide good multimodal embeddings?
- can we use the generator to visualize crossmodal mappings?
Multimodal Fusion
Regarding the first question, we compare this method with the previous state of the art BiDNNs and a classical multimodal autoencoder and obtain the following:
| Representation | Prec@10 | σ |
|---|---|---|
| Speech Only | 56.55 | - |
| Visual Only (VGG-19) | 52.41 | - |
| Multimodal AE | 57.94 | 0.82 |
| BiDNN | 59.66 | 0.84 |
| DCGAN | 62.84 | 1.36 |
We obtain high quality multimodal embeddings with a generative adversarial network that outperform the previous BiDNN state of the art with a slightly increased standard deviation. With a one sided T-test we can see that this new method significantly outperform BiDNNs (p=99.9%).
However, we have to have it mind the huge current downsides of this new GAN based method:
- the image are of size 64x64 and it's currently very difficult to deal with bigger images - with a BiDNN, it's easy to use a CNN representation of bigger images and obtain way better results (we obtained 80% on this dataset when not being limited to images of size 64x64)
- training, even for such small input sizes, takes a lot: 2 days on a Titan X GPU with Pascal architecture - with a BiDNN, it's possible to obtain better embeddings (due to bigger input sizes) in just a few hours, without a GPU
This is likely to change in the future, when better GAN architectures (that can converge and synthesize even bigger image sizes) and with hardware improvement. However, for now, my personal opinion is that for solely obtaining state of the art multimodal embeddings, BiDNNs are the way to go.
Crossmodal Visualizations
This is what I find most interesting in this architecture, the ability to visualize a crossmodal model in a human interpretable form. Let's see a few examples of synthetic images created by the model given a speech segment:
| Input - Automatic Speech Transcript | Generated Images | Real Image |
|---|---|---|
| "... insects emerged to take advantage of the abundance . the warm weather sees the arrival of migrant birds stone chests have spent the winter in the south..." |  |
 |
| "... second navigation of the united kingdom . the north sea , it was at the north yorkshire moors between the 2 , starting point for the next leg of our journey along the coast..." |  |
 |
| "... this is a dangerous time for injuries for athletes . having said that , some of these upbeat again a game . there she is running strongly she looks more comfortable..." | 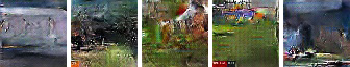 |
 |
| "... the role of my squadron afghanistan is to provide the the reconnaissance capability to use its or so forgave so using light armor of maneuvering around the area of..." |  |
 |
It's interesting to see how in the last example, the model synthesizes news presenters when hearing war thematics while the real video contained footage from an actual war zone. The synthesized images are not perfect but they provide easy to understand visual insight to the learnt crossmodal translation learnt by the model.
We can visualize the opposite crossmodal translation by inverting the architecture of the discriminator (transposing convolutions and slicing the obtained vector) and by finding words that are closes to the representation obtained for an input image. A few examples follow:
| Input Image | Top Words in the Speech Modality |
|---|---|
 |
britain, protecting, shipyard, carriers, jobs, vessels, current, royal, aircraft, securing, critics, flagships, foreclosures, economic, national |
 |
north, central, rain, northern, eastern, across, scotland, southwest, west, north-east, northeast, south, affecting, england, midlands |
 |
pepper, garlic, sauce, cumin, chopped, ginger, tomatoes, peppers,,onion,,crispy, parsley, grated, coconuts, salt, crust |
 |
mountains, central, foreclosures, ensuing, across, scotland, norwegian, england, country, armor, doubting, migration, britain, southern |
Future Work
While there results are promising and the visualizations are interesting, this system is too heavy (training time) and limited (image size) to use in practice in its current state. It'd be interesting to use more recent GAN architectures that allow for bigger image sizes.
Additionally, this model translates from the speech representation space to the image domain. It'd be very interesting to integrate a (gated) RNN and allow it to go directly from speech to images. This is what I originally wanted to do but time constraints didn't provide me the opportunity to try to go full original-domains-crossmodal.
View on Google Scholar
Will be made available soon.